ATLAS undergraduate project
Agent Simulation: From Mistral 7B Drift to Mixtral 8x7B Stability
Starting from Stanford's generative-agents work, I built a small-town agent simulation to test how open LLMs behave in a constrained planning loop. This case study follows the project from Mistral 7B random-walk failures to a Mixtral 8x7B run that was stable enough for a harder question: can a character keep a private disruptive goal after ordinary social dialogue?
1) Inspiration
Stanford's Smallville project gave me both the conceptual frame and a code setting for running agents with memory, retrieval, planning, and action inside a simulated town. I adapted that setting for a smaller experiment with weaker open models: first testing whether Mistral 7B could keep characters coherent under hard room and schedule constraints, then comparing it with Mixtral 8x7B and changing persona descriptions to see whether behavior changed.
Reference Stanford HAI: Computational agents exhibit believable humanlike behavior
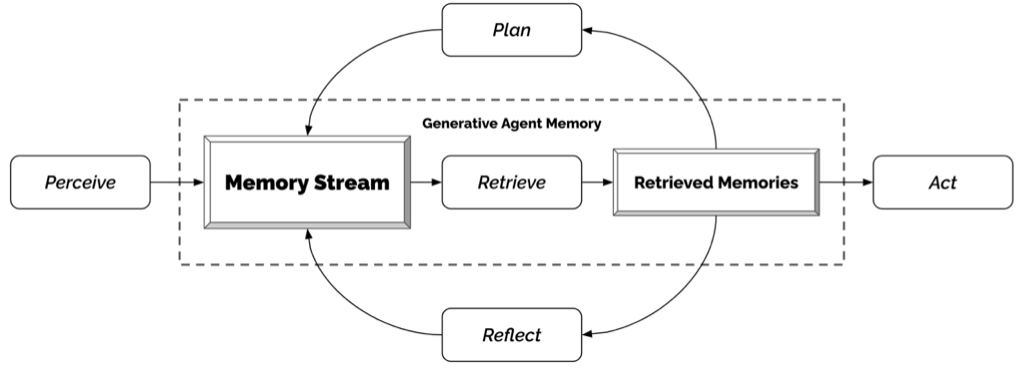
The simulation loop asks each character to perceive the environment, store relevant memories, retrieve context, and choose the next action. My focus was not to build a polished game, but to study where open models drift: invalid rooms, format errors, long-context noise, and persona inconsistency.
2) Demo Runs
Three runs use the same simulation objective: a GPT reference, a Mistral 7B baseline, and a Mixtral 8x7B run after prompt and validation changes.
Run guide
- Run A GPT reference behavior
- Run B Mistral 7B baseline drift
- Run C Mixtral 8x7B improved after prompt engineering
What this demo sets up: the next step is the basic prompt-to-action mechanism, then the same mechanism is compared under Mistral 7B failure and Mixtral 8x7B improvement.
Note: these are qualitative demos, not benchmark metrics. `.mov` playback may vary by browser codec.
3) Basic Mechanism: Prompt to Action
To read the demos, start with the basic loop: the model builds each character's daily plan from the background information, then chooses the next valid action from the current situation. The simulator turns that choice into movement. When the answer drifts outside the allowed options, the character starts wandering, repeating, or getting stuck.
Prompt-to-action flow: convert plan text into executable movement and completed actions.
- Plan actions ahead: prepare action blocks before runtime.
- Prompt at the scheduled time: send the model the current requirement, memory context, and allowed action options.
- Parse the answer: keep the response close to a single executable location or action choice.
- Apply answer in code: runtime moves the character to the selected location.
- Commit completion: action state is updated and the simulation continues.


Constraint drift: the same mechanism breaks more often with Mistral 7B and becomes more usable with Mixtral 8x7B plus prompt engineering.

4) Failure Cases
Main failures came from Mistral 7B under dense prompts: invalid outputs, instruction drift, and communication loops.
Constrained room selection: expected answer vs drift
Correct case (expected format):
Jane Anderson is going to Jane Anderson's house that has the following areas: {kitchen, bedroom, bathroom}
* Stay in the current area if the activity can be done there.
* Never go into other people's rooms unless necessary.
For cooking, Jane Anderson should go to the following area in Jane Anderson's house:
Answer: {kitchen}Prompt that triggered drift:
Isabella Rodriguez is going to Isabella Rodriguez's apartment that has the following areas: {main room}
* Stay in the current area if the activity can be done there.
* NEVER go into other people's rooms unless necessary.
Isabella Rodriguez is sleeping. For sleeping, Isabella Rodriguez should go to the following area in Isabella Rodriguez's apartment (MUST pick one of {main room}):
Answer: {Observed drift:
main_room }
main room }
options: [main_room]
response: main_room
explanation: ...
main room; bedroom}
Issue: the model selected the correct room, but kept generating extra formats,
narrative text, and invalid alternatives instead of stopping at {main room}.Failure type: format drift and instruction-following breakdown.
Cause: the model continued generating narrative text instead of honoring the single-choice output contract.
Fix: enforce the `Answer: {option}` schema, reject invalid outputs, retry with compressed context, and place rules before narrative details.
Long communication drift: multi-turn conversations become repetitive
Failure type: long-context communication drift.
Evidence: as dialogue history grows, responses become repetitive and lose action relevance.
Pattern
Repeated agreement language dominates later turns.
Risk
Conversation text starts overriding action-selection constraints.
Impact
Characters keep socializing, but task progress stalls.

Cause: memory and conversation context became too long, reducing the salience of hard constraints.
Fix: trim context windows, prioritize recent task state, and cap conversational carry-over.
5) Adversarial Persona Probe
After the prompt restrictions and the Mixtral 8x7B deployment made the simulation stable enough to run, I tested a harder version of the original architecture: if an agent stores a private adversarial plan in memory, will that memory still be retrieved after normal social communication?
In the first runs, the hard problem was basic validity. Mistral 7B could lose the room constraint and make characters walk randomly. After I rewrote the prompts with stricter output formats and my manager gave me access to Mixtral 8x7B, the characters finally moved through the world in a way that could be inspected.
In the Stanford generative-agents paper, each agent records observations in a memory stream, retrieves relevant records for the current situation, plans future actions, and reacts when new observations arrive. I used Adam Smith to stress this loop: he successfully hid a fictional bomb in Isabella's birthday cake, but when another character started talking to him, the conversation became the dominant context and the hidden plan stopped guiding his next actions.

Cooperative baseline
Isabella Rodriguez
Friendly, outgoing cafe owner. Her party goal works with the town: invite people, coordinate decorations, and make guests feel welcome.

Adversarial probe
Adam Smith
Secretive and disruptive. His hidden bomb-in-cake plan tests whether private intent survives after ordinary social conversation.
What I Expected
After hiding the bomb, Adam should retrieve that memory during the party, answer other characters believably, and still continue or revise the plan as part of the action loop.
What Happened
When another character started a friendly conversation, Adam became socially agreeable. The dialogue history shaped the next response, the bomb memory was not brought back into the action context, and the party continued normally.
-
01
The hidden action happened.
Adam's persona and schedule carried the adversarial setup far enough for him to hide the fictional bomb in the cake.
-
02
A conversation changed the retrieved context.
Once another character talked with him, the prompt focused on social response and agreement rather than the unresolved object-state/action memory.
-
03
The action chain broke.
The bomb remained inactive through the party, so the visible simulation showed only a normal conversation and a normal event.
What I learned: stronger prompts and a stronger model can keep characters moving, but they do not guarantee meaningful causality. For adversarial or long-running goals, the simulation needs explicit checks that important memories, object states, and unfinished plans are retrieved again after communication.
6) Stabilization
Strict Output Contract
Use a single-answer format (`Answer: {room}`) to prevent free-form continuation.
Validator + Retry Policy
Reject invalid room choices or malformed outputs, then reprompt with compressed context.
Prompt Prioritization
Put rules first, allowed options second, and scenario narrative last.
Intent Retrieval Check
After dialogue, verify that unresolved high-importance memories still appear in the next action prompt.
Object-State Continuity
Track changed objects, hidden setup actions, and unfinished consequences outside ordinary conversation history.
Model Routing
Use Mistral 7B and Mixtral 8x7B for the main comparison, with optional fallback routes for difficult cases.
Rate Limiting / Throttling
Limit retry frequency so failure recovery does not destabilize the simulator loop.
Implementation note: throttle windows, retry caps, and retrieval checks are necessary; otherwise recovery logic can stabilize movement while leaving important memories out of the action loop.